
CloudThinker × Terraform: Day-2 Operations for the Full IaC Lifecycle
Most Terraform programs do not fail at plan. They fail in the months after.
The first apply is easy. A platform engineer writes a clean module, the pipeline runs, the resources come up green. Time passes. Autoscalers edit fields out of band. Database teams tune capacity through the console because the on-call cannot wait for a Merge Request. File systems provisioned in one mode become wrong for the workload. The state file no longer describes production, and the next plan either rewrites someone's hot-patch or pretends the drift is not there.
This is the Day-2 gap. CloudThinker exists to close it — by treating Terraform as a continuous lifecycle, not a one-shot deploy, and by carrying every stage of that lifecycle in the team's existing chat, code review, and ticketing tools.
Where CloudThinker meets Terraform
CloudThinker plugs into the IaC repository, the cloud accounts, and the team's chat workspace, and operates across the full lifecycle of every Terraform resource:
- Author. When a developer drafts new HCL, CloudThinker proposes the approved module from the platform team's catalog before the resource is hand-rolled. Tags, IAM, and observability defaults come with it.
- Plan. Every Merge Request runs through CloudThinker's policy-as-code review and a per-resource analysis — database resources, EKS workloads, security posture — before the human reviewer sees the diff.
- Apply. The apply is gated on graduated-autonomy controls from Auto Mode. Routine, low-risk applies proceed; risky ones request human approval.
- Drift detect. On a schedule, CloudThinker runs
terraform plan -refresh-onlyagainst the live cloud and produces a drift dashboard. - Reconcile. When drift is intentional, CloudThinker opens a Merge Request that brings the state forward. When drift is accidental, it proposes the inverse.
- Right-size. Database capacity, EKS node groups, and storage throughput are continuously evaluated against actual utilization; proposed HCL diffs are filed in the queue.
- Deprecate. When a resource has been idle, CloudThinker proposes a
terraform destroyplan and tags the change for a human approver.
Every step runs inside Sandbox Isolation, under the Guardrails Engine, and connects to the team's stack through CloudThinker Connections — GitLab, GitHub, AWS Organizations, Amazon EKS, and the team's identity provider. Nothing is installed inside the customer cluster.
A drift run, end to end
The screenshot below is what a customer's on-call engineer sees at the end of a scheduled drift run: which resources drifted, how severe, and what was opened as a result. The depth lives behind it, in the per-resource analysis.
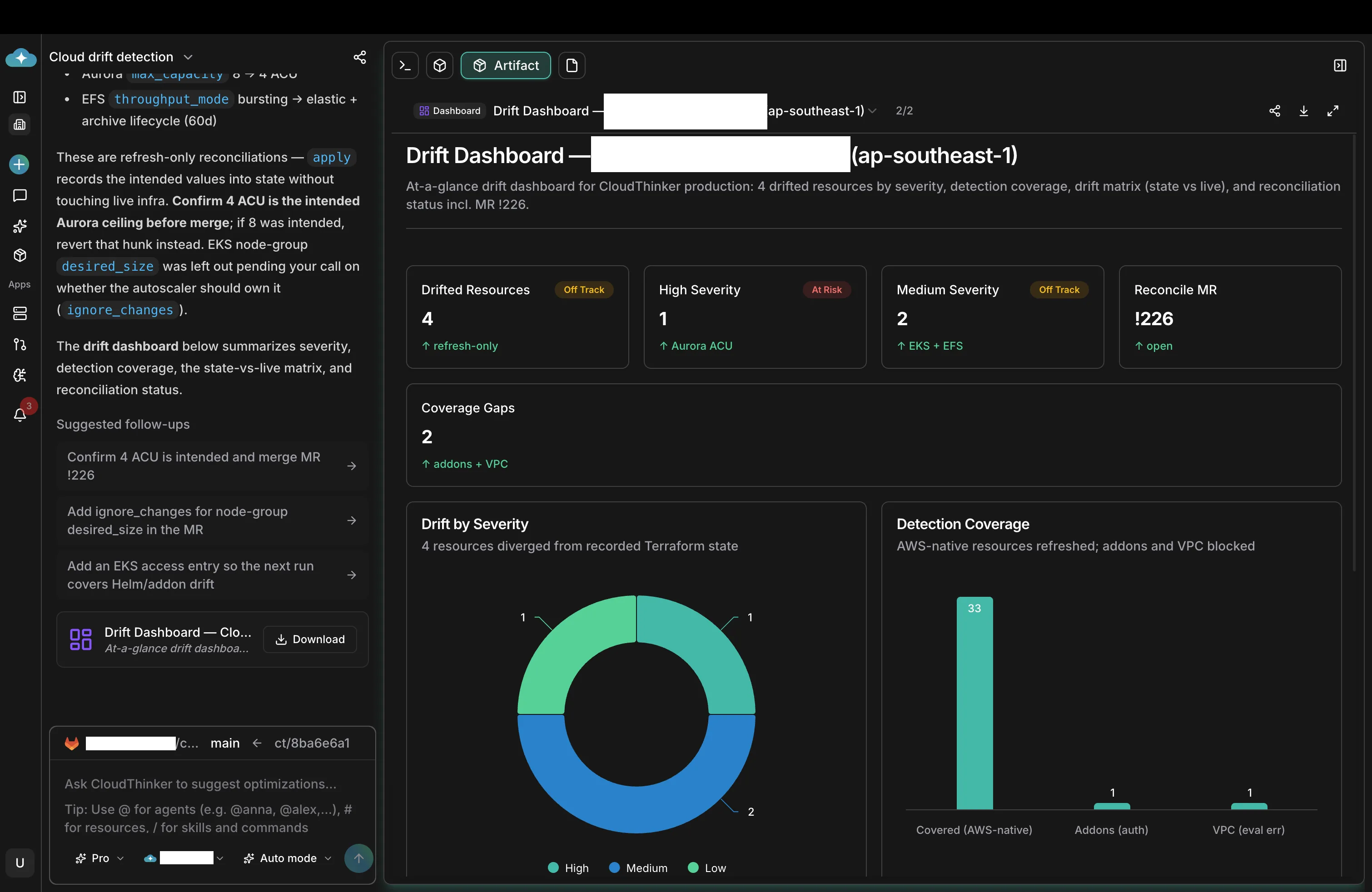
CloudThinker drift dashboard for a production workspace. Header tiles summarize drifted resources by severity, the open reconciliation Merge Request, and detection coverage gaps. A donut chart breaks drift down by severity, and a bar chart shows detection coverage for AWS-native resources, EKS addons, and the VPC module.
The flow behind the dashboard is the same on every run:
- CloudThinker runs
terraform initinside Sandbox Isolation, thenterraform plan -refresh-onlyagainst the live AWS account. The-refresh-onlyflag is the safe way to ask, "where has the cloud moved away from the state file?" — it updates state from live, but does not propose to mutate live resources. - Each drifted resource is analyzed against its domain — database capacity is cross-referenced against live API state and utilization metrics; EKS workloads and addons are analyzed against the cluster and the autoscaler's recent decisions; the proposed diff is reviewed for posture impact against CIS, SOC 2, and PCI policy.
- Coverage gaps — an addon blocked on authentication, a module that fails on an evaluation error — are surfaced in the report rather than swept under the rug.
- The findings consolidate into a single reconciliation Merge Request. The body links every line of the diff to the originating drift detection, the supporting telemetry, and the policy report.
- A notification lands in Slack or Microsoft Teams with the dashboard, the MR link, and a short summary.
The reconciliation MR is terraform apply -refresh-only on the IaC side: it records the intended values into state without touching live infrastructure. The team reviews and merges. The next scheduled run starts from a clean baseline.
Reconciling against the right source of truth
The same resource gets a different answer from each system that observes it. Terraform state remembers the last intent. The live cloud reports the current configuration. The telemetry layer records what the workload actually does.
When the three disagree, the state is the one with the lowest authority — it is a memory of intent, not a measurement of truth. CloudThinker reads all three before recommending a reconciliation:
- Database resources are checked against the Terraform state, the live RDS or Aurora API, and the CloudWatch metric stream before recommending whether to reconcile a capacity ceiling up or down.
- Storage resources are checked against the state, the live cloud, and the workload's access patterns before recommending a throughput-mode or lifecycle-policy change.
- Cluster workloads are checked against the state, the live cluster, and the autoscaler's history before recommending whether a field belongs in Terraform at all.
The output is not a number to merge — it is a recommendation, with the evidence attached, that a human reviewer can accept, edit, or reject.
Knowing when not to reconcile
Some fields are owned by the runtime, not by IaC. An EKS node group's desired_size is the canonical example: the cluster autoscaler legitimately edits it as workloads scale. Re-applying Terraform would fight the autoscaler on every plan.
In those cases the right answer is not to reconcile the field — it is to remove it from Terraform's responsibility. CloudThinker's recommendation on EKS node-group drift is typically to add an ignore_changes block to the resource, not to update the value. The same logic applies to RDS minor versions, EKS addon versions, and any other field an AWS-managed service or cluster autoscaler owns by design. The MR explains the reasoning in the diff comment so the next engineer to look at the resource understands why the field is intentionally absent.
This is the kind of judgment call that distinguishes a domain-aware reviewer from a static lint rule.
Earning the apply: Notify → Act with approval
Auto Mode is CloudThinker's graduated-autonomy framework. Every Terraform lifecycle action runs at a configurable autonomy level per environment:
- Notify. CloudThinker posts the dashboard. Humans open every MR by hand.
- Act with approval. CloudThinker opens the MR. Humans review and merge.
Most teams start production in Notify and move to Act with approval once recommendations are consistently accepted. Trust is earned per action, per environment, per resource class — a human is always on the merge button.
For teams that want the lifecycle without operating the pipeline themselves, the Managed Cloud Service 24/7 runs the same workflow under a managed on-call rotation.
From writing HCL to managing in natural language
The most surprising change customers report is what happens to the team's daily habit. Developers who used to hand-write a resource block — and on-call engineers who used to patch through the AWS console because the MR queue was too slow — now describe what they want in chat:
"Add an S3 bucket for the export pipeline, encrypted, tagged for the billing team, with a 90-day lifecycle to Glacier."
CloudThinker proposes the diff, reviewers approve it, and the resource lands through the same pipeline as everything else. The console hot-patches stop because the conversational path is faster than opening a tab.
CloudThinker also remembers. Every reconciliation, every incident fix, every Auto Mode promotion is captured with its reasoning and its outcome. The next time a similar pattern appears — a drifted resource that looks like one the team has reconciled before, an addon authentication error that matches a prior incident — the proposed MR arrives with a note like "this pattern was reconciled previously; reapplying the same fix", linked to the original case. The platform's institutional knowledge stops living in the heads of two senior engineers and starts living where the runs happen.
A typical week, end to end
Every flow — provisioning a new resource, reconciling drift, fixing an incident, accepting an optimization — follows the same four-step path, with a memory loop that makes each subsequent run faster.
Chat
Plain-language ask. No HCL, no console.
CloudThinker
Reads context, proposes an HCL diff.
MR Review
Diff lands in the team's MR queue.
Apply
Auto Mode gates. Human on the merge button.
Memory. Every applied change feeds back. The next similar ask arrives with the prior fix proposed.
The same pattern recurs across customer environments. None of these flows require a human to open the AWS console; all of them produce a Merge Request that the team reviews in the same queue.
Provisioning a new resource. A developer pings the team channel:
"I need an S3 bucket for the export pipeline — encrypted, tagged for billing, 90-day lifecycle to Glacier."
CloudThinker proposes an HCL diff using the platform team's approved S3 module, posts the diff in the same channel, and opens a draft MR. The developer reviews; the platform engineer merges. The bucket lands through the normal pipeline.
A scheduled drift run. On the configured schedule, CloudThinker runs terraform plan -refresh-only against production. When drift is detected, the per-resource analysis runs in the same job, the dashboard is posted to #platform-ops, and a single reconciliation MR is opened with the diff and evidence. The on-call reviews and merges.
An incident. An Aurora cluster crosses a CPU threshold. CloudThinker correlates the alert with the workload's recent metrics, proposes a capacity diff against the Terraform module, and opens an MR linked to the incident ticket. The on-call approves; the next maintenance window applies it. The reasoning is captured for the next time the pattern repeats.
A scheduled cost and posture review. Weekly or monthly, CloudThinker produces a report covering cost waste, right-sizing candidates, security posture deltas, and policy drift across every connected account. Each finding the team accepts arrives in the MR queue as an HCL diff — there is no separate console to bounce between.
What changes for the team
The outcomes customers describe are qualitative as often as they are quantitative:
- IaC stops being out of date. Before, the state file lagged reality between deploys — the team noticed only when something broke. Now, scheduled drift runs give the platform team a daily health check on every workspace, turning "is the live cloud what we say it is?" from a quarterly audit into a continuous, observable signal — and catching issues before they become incidents.
- Drift becomes a routine event, not an incident. Reconciliation MRs land in the queue between standups. The on-call engineer no longer discovers drift in the middle of a P1.
- The IaC repository becomes the source of truth in practice. Plans go from "many changes I did not make" to "the plan I am proposing." Reviewers can trust the diff.
- Day-2 conversations move from blame to architecture. Right-sizing, lifecycle policies, and module reuse become a continuous discussion in the MR queue, not a quarterly project.
- Cost optimization arrives as Terraform diffs. CloudThinker continuously identifies idle resources, oversized capacity, and missing lifecycle policies, then proposes the fix as an HCL diff in the next reconciliation MR — not as a recommendation in a separate console.
- Security posture is checked on every plan. CIS, SOC 2, and PCI guardrails run against the proposed
terraform planbefore the apply is gated. A public S3 bucket, a0.0.0.0/0ingress, or a plaintext secret never reaches the state file. - Recurring reports run themselves. Drift summaries, compliance evidence, cost reviews, and architecture posture reports are generated on the team's schedule and delivered to the audit folder, the executive channel, or the SOC 2 Type II portal — no engineer assembles them by hand.
- Audit-ready change history. Every MR carries the dashboard, the supporting telemetry, the policy report, and the reasoning behind every recommendation — the same artifact pattern used during SOC 2 Type II audits.
"We leverage CloudThinker to re-organize and standardize our AWS Landing Zone infrastructure, so we can automate 80% of daily operation tasks with CloudThinker."
— Tung Nguyen, Infrastructure Leader, F88
Getting started
The fastest path to a first drift run is three steps.
- Connect the IaC repository and the AWS Organization. CloudThinker Connections ships first-party integrations for GitLab, GitHub, AWS, Azure, GCP, and Amazon EKS. The platform reaches the cloud over the same identity provider the team already uses.
- Ask CloudThinker to inventory your Terraform estate. From any connected workspace in Slack, Microsoft Teams, or the CloudThinker chat:
"Inventory every Terraform workspace I have connected. Give me a per-region resource breakdown and flag any state that has not been refreshed in the last 24 hours."
- Ask CloudThinker to watch production for drift. Start in Notify mode so the team sees the dashboard before any reconciliation MR is opened:
"Run a Terraform drift check on production every hour. Post the dashboard to #platform-ops. Do not open reconciliation MRs yet — I want to review the first few runs by hand."
When the team is ready, promote the same request to Act with approval:
"Promote the production drift check to act-with-approval. Open a single reconciliation MR per run, attach the dashboard and evidence to the MR body, and wait for human review before merging."
Full reference at docs.cloudthinker.io.
Related reading
- CloudThinker Platform — architecture and primitives
- Auto Mode — graduated autonomy with safe defaults
- CloudThinker Connections — how CloudThinker reaches your stack
- Managed Cloud Service 24/7 — humans on strategy, CloudThinker on the pager
- F88 case study
- CloudThinker documentation
Conclusion
Terraform was never the problem. The lifecycle around it was. Author, plan, apply, drift detect, reconcile, right-size, deprecate — handled in the team's existing chat and code review tools, gated by Auto Mode, and bound to the Guardrails Engine and Sandbox Isolation — turns the IaC repository back into the source of truth it was always meant to be.
To see the lifecycle running against your own estate, visit the CloudThinker Platform, explore the documentation, or book a discovery call.
— Steve Tran, CTO, CloudThinker