CloudThinker Agentic Orchestration and Context Optimization
1. Introduction
We've all built chatbots. They are great at answering questions, but terrible at doing actual work. The industry is shifting from reactive chatbots to autonomous agentic systems, but this transition isn't free.
When we started building CloudThinker, we wanted more than a chat interface. We wanted an AI that could wake up, analyze a skyrocketing cloud bill, fix the database config causing it, and send us a report—all without us typing a word.
But moving from "talking" to "doing" is hard. Single-agent architectures eventually hit a wall with long-running workflows. They can't distribute specialized tasks, parallelize operations, or manage the exponential token growth that comes with complex reasoning. If you're not careful, they burn through $50 of tokens in ten minutes just to tell you "I don't know."
We built CloudThinker to solve these scale problems. By implementing novel context optimization techniques—prompt caching, asynchronous context compaction, and parallel tool calling—we achieved 80-95% cost reduction, 7x faster task completion, and 85% latency reduction compared to our baseline.
Here is the architecture we built to achieve those numbers, and the production lessons we learned moving from a fragile prototype to a system that actually works.
2. Multi-Agent Architecture Deep Dive
Multi-agent orchestration unlocks the potential of specialized AI systems, but success hinges on coordination strategy. How do you prevent chaos when multiple agents work simultaneously?
2.1 The Coordination Verdict
Let's be clear: Always start with a single agent.
Multi-agent orchestration is cool, but it's a nightmare to debug. We didn't switch to a team of agents because it was trendy. We switched because our single agent hit a ceiling. It couldn't be an expert in Kubernetes and billing and security all at once. It started making mistakes. Only then did we accept the "complexity tax" of building a team.
The Evolution: From Single-Agent to Supervisor
Our architecture didn't start with specialists. It evolved because we looked at the metrics. We compared three fundamental approaches:
| Pattern | Coordination Model | Verdict |
|---|---|---|
| Single-Agent | No coordination needed | ❌ The Ceiling: Great for simple tasks, fails hard on complex ones. |
| Network (Peer-to-Peer) | Distributed consensus | ❌ The Trap: Like a committee meeting with no agenda. Lots of talking, no decisions. |
| Supervisor | Centralized coordinator | ✅ The Solution: Clear ownership. One boss, many workers. |
- Single-Agent (The Baseline): Always start here. We ran a single generalist agent until it started failing on complex, multi-domain tasks. Don't pay the "coordination tax" until you have to.
- Network/Peer-to-Peer (The "Chaos" Trap): We tried letting agents talk directly to each other. It was a mess. Without a boss in the room, they argued in infinite loops about who should check the database.
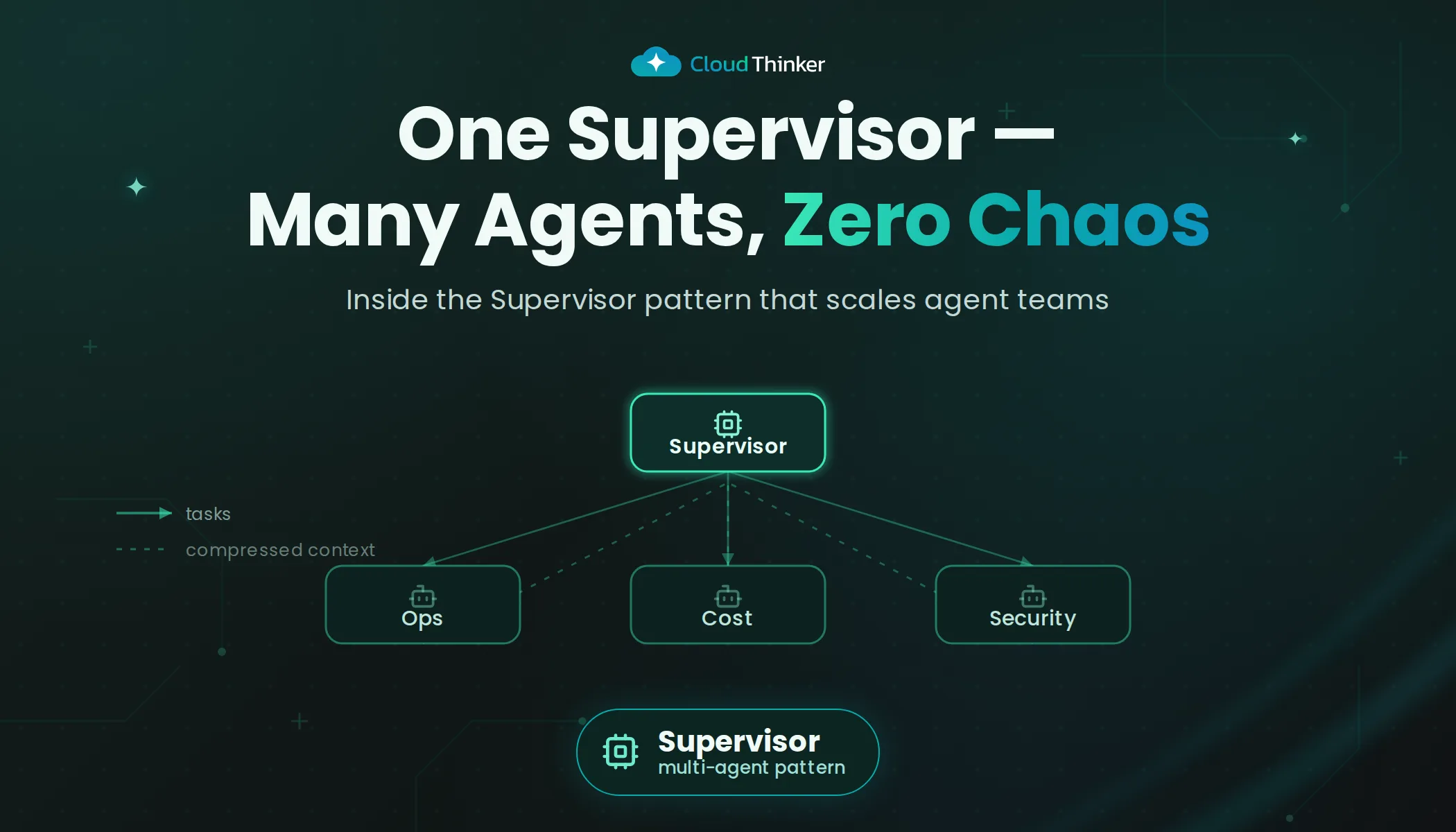
- The Winner: Supervisor Pattern: We settled on the Supervisor Pattern (Anna - General Manager). It gave us the reliability we needed: one agent whose only job is to make sure the work gets done.
We standardized on the Supervisor Pattern (Anna - General Manager). This provides the "Production-Ready" reliability we needed: clear ownership, explicit routing, and a central point for state management.
2.2 Choosing the Right Supervisor Variant
Once we decided on a Supervisor, we had to pick a management style.
| Variant | When to Use | Trade-offs |
|---|---|---|
| Flat Supervisor | Small teams (2-10) | ✅ Simple, reliable ← CloudThinker uses this |
| Supervisor (as tools) | Delegation | ⚠️ Less autonomy, tighter coupling |
| Hierarchical | Large Orgs | ⚠️ Good for scale, bad for latency. Adds middle management. |
| Custom Graph | Complex dependencies | ❌ Flexible, but debugging it is miserable. |
- Flat Supervisor (CloudThinker's Choice): We stuck with the simplest option. We have distinct domains (Compute, Database, Security), so a single flat layer is enough.
- Hierarchical: Only use this if you're building a massive system. If you need a "Support Team" that handles tickets without ever bothering the main manager, this makes sense. Otherwise, it's just extra layers.
- Custom Graph: Avoid this unless you hate yourself. In production, we prefer boring and predictable over "flexible" and broken.
Production Insight: Start with the Flat Supervisor. It incurs the lowest "coordination tax" while providing sufficient separation of concerns. Only move to Hierarchical if you need to scale beyond 10 agents or require strict "Transfer" patterns where sub-teams operate completely independently.
2.3 Routing and Activation: Optimistic Routing with Fail-Safes
In theory, the Supervisor should manage everything. In reality, that's slow and expensive. Why ask the manager for permission to check the time?
We use Optimistic Routing—we assume the specialist can handle it, but we keep a safety net.
- Default to the Specialist (Fast Path): If you ask "Show running instances," we send you straight to Alex (Cloud Engineer). No meeting with the boss required. Zero orchestration overhead.
- Contextual Continuity (Sticky Sessions): If you're already talking to Tony about a database issue, we keep you there. It's annoying to be transferred back to the main menu every time you reply.
- The Escalation Safety Net: This is the "fail-safe." If you ask Alex (the cloud guy) "Why is my RDS slow?", he doesn't try to guess. He says, "That's not my job," and escalates back to Anna (Supervisor). She then assigns it to the right person. Complex tasks never fail silently; they just get escalated.
Why this matters: This approach cuts latency by 40-50% for most tasks. We keep the speed of a single agent but the power of a full team when we need it.
2.4 Agent Communication Protocol
If you think getting three humans to agree on a lunch spot is hard, try getting three AI agents to debug a database.
Without strict rules, multi-agent chats turn into "context pollution"—agents confusing each other with irrelevant data until the whole system crashes.
We solve this with a Group Chat Protocol that enforces two simple rules:
- Explicit Targeting: You can't just "talk." You must address someone (
@alex,@anna). If you don't, the message is rejected. - Structured Handoffs: You can't just dump a 50-page log file into the chat. You have to summarize it first.
Within this framework, we use two patterns to move work around: Delegation (The "Boomerang") and Transfer (The "Handoff").
Delegation: The "Boomerang" Pattern

Delegation Pattern
Complex infrastructure workflows require multiple specialized agents working in sequence, but naive implementations create two critical problems: (1) exponential token growth when each agent inherits all previous context, and (2) coordination failures when handoffs lose critical task state. Delegation solves this through structured task assignment where supervisors retain accountability while workers execute specialized operations.
Consider a multi-stage AWS cost optimization workflow: (1) Alex (Cloud Engineer) gathers EC2 spending data, (2) Anna (General Manager) analyzes spending patterns and identifies database cost anomalies, (3) Tony (Database Engineer) investigates RDS configuration and proposes optimizations. This can't be a direct transfer—Anna needs Alex's cost data to provide strategic context to Tony, but Tony shouldn't inherit Alex's verbose CloudWatch API outputs (potentially 50K+ tokens). Delegation enables this through structured handoffs: Anna delegates to Alex → Alex executes and returns summarized results to group chat → Anna takes results, analyzes, then delegates to Tony → Tony executes with only Anna's analysis context, not Alex's raw outputs.
Delegation operates through the group chat tool with explicit continuation markers. The critical optimization: Tony receives Anna's 200-token delegation message with strategic context ("no compute correlation"), not Alex's 50K-token CloudWatch dumps. Anna maintains accountability—she's waiting for Tony's results to compile the final optimization plan.
Token Economics and State Management
Each agent maintains isolated message history—when Agent A delegates to Agent B, only the handoff message appears in Agent B's context, not Agent A's tool outputs. With this context isolation approach:
- Agent A: 50K tokens → produces 200-token summary
- Agent B: 200 tokens (A's summary) + 30K (B's work) = 30.2K tokens → produces 200-token summary
- Agent C: 200 tokens (B's summary) + 20K (C's work) = 20.2K tokens
- Total: 100.4K tokens processed (56% reduction)
In production CloudThinker workflows, delegation with context isolation achieves 50-70% token reduction compared to shared-context implementations, directly reducing inference costs and latency.
Trade-offs and Production Considerations
Delegation introduces coordination overhead—each handoff requires supervisor reasoning about which specialist to activate and what context to provide. In our metrics, delegation adds around 5 seconds per handoff for supervisor decision-making, acceptable for complex workflows but unnecessary for simple single-specialist tasks. The most common anti-pattern is delegating too early: if the supervisor hasn't completed its analysis phase, delegation becomes premature—"@alex go check EC2 costs" without specifying what patterns to look for forces unnecessary back-and-forth. The supervisor must provide sufficient task framing before delegating. Error handling adds further complexity—when a worker fails mid-delegation chain, the supervising agent must decide: retry with the same specialist, escalate to a different specialist, or abort the workflow. Production systems require explicit error handling policies; our implementation uses a 3-retry policy with exponential backoff before escalating to the user.
Transfer: The "Handoff" Pattern

Transfer Pattern
Not all multi-agent workflows require supervisor oversight. Transfer provides complete ownership handoff for simple, domain-specific queries—the supervisor exits, the specialist takes full control, and all subsequent user interactions happen directly with the specialist. The choice hinges on two questions: (1) Does the task require multi-specialist coordination? (2) Will the supervisor need the results for subsequent analysis? If both answers are "no," transfer is optimal.
Transfer applies to single-specialist queries: "What's our PostgreSQL version?" or "Show current Kubernetes pods." Delegation handles multi-stage workflows: "Why did costs spike?" (requires coordination) or "Investigate API slowness" (requires multiple specialists).
Transfer eliminates supervisor overhead by archiving the supervisor's state after handoff—no callbacks needed. Production metrics show cost reduction and 50% latency reduction compared to delegation (10.2K tokens → 7.2K tokens, ~4-6s → ~2-3s). However, the most common failure is premature transfer: supervisors must complete decomposition before handing off.
- ❌
"App has high latency" → "@alex investigate"(too vague). - ✅
"API response times 200ms→1.8s at 14:00 UTC" → "@alex investigate infrastructure causes"(sufficient context). Transfer only when the specialist has sufficient context to execute independently.
3. Context Optimization Techniques
Multi-agent orchestration solves coordination challenges but introduces a new problem: token explosion. Four techniques form our optimization strategy—prompt caching, asynchronous context compaction, tool consolidation, and parallel tool calling.
3.1 Prompt Caching
The ratios between chatbot and agentic systems are dramatically different. Chatbot systems typically have a 3:1 input-to-output token ratio, while agentic systems can reach 100:1 ratios. This is because agentic systems need to reason, plan, and execute tasks through multiple tool calls—often 50+ per task. Input token costs dominate total expenses, making prompt caching critical for production viability.
Prompt caching (also called KV cache) allows LLMs to reuse previously computed context across API calls, delivering two critical benefits: cost reduction and latency improvement. Most implementations charge a premium for cache writes but deliver significant discounts on cache reads (often 80-90% cost reduction) and up to 85% latency reduction on cached requests. Cache hits also dramatically reduce time-to-first-token (TTFT)—the model skips reprocessing cached context and immediately begins generating output. After just a few API calls reusing the same context, the economics shift dramatically in your favor.
The Cache Breakpoint Challenge
The rule is simple: Cache everything static. Keep dynamic stuff at the end.
But "static" is trickier than it looks. As the Manus team discovered, a single timestamp in the wrong place can invalidate your entire cache. We treat Cache Hit Rate as a top-level KPI. If it drops below 90%, we treat it like a production outage.
Three-Tier Objective Prompt Strategy
Following the Manus team's insight that objective prompts should be placed outside cache boundaries, we use a "Three-Tier" architecture to maximize cache reuse while preserving turn-by-turn adaptability:

Three-Tier Prompt Caching Strategy
The diagram illustrates the critical optimization: the cache checkpoint moves forward after each completed turn. At Step N, the agent generates Action 1 and receives Observation 1. At Step N+1, these completed interactions move behind the checkpoint—now cached and reusable. The Objective (containing live context like team composition, active resources, and current plan) remains after the checkpoint, regenerated each turn with updated information. By Step N+2, both previous action-observation pairs are cached. This "moving breakpoint" strategy ensures all historical work gets cached while only the dynamic objective block is reprocessed each turn. Compare this to naive implementations that modify system prompts or insert content mid-history—those approaches invalidate the entire cache on every API call.
The three-tier structure:
- Tier 1 - Static System Prompt: Tool schemas and core behavioral rules. Cache write on first call, then cache hits forever (95%+ hit rate across conversations)
- Tier 2 - Conversation History: Actions and Observations accumulate as the agent works. The cache checkpoint moves forward after each completed turn, preserving all historical context
- Tier 3 - Dynamic Objectives: Always placed AFTER the checkpoint. Contains live context (team composition, connected resources, active plan, memory retrieval results). Never cached—regenerated each turn with current state
Key Insight: By keeping dynamic content at the end, everything upstream remains cacheable. As conversations grow longer, the cache absorbs the majority of tokens while only the small objective block is reprocessed per turn—the foundation of the 80-95% cost reduction.
3.2 Asynchronous Context Compaction
Caching saves money, but you eventually run out of space. Even with a 200k context window, a multi-hour infrastructure analysis can fill the buffer with tool outputs and reasoning traces.
The standard industry solution is "summarization," but the way most teams implement it destroys both User Experience (UX) and accuracy.
The Failure of Synchronous Summarization
We initially ran summarization synchronously: when the window hit 90%, the agent would pause, call a separate "Summarizer Agent" to compress the history, and then resume.
This failed for two reasons:
- The "Please Wait" Problem: Users were left staring at a spinner for 45 seconds in the middle of a debug session while the system "cleaned up." It killed the flow.
- The "External Summarizer" Gap: Our benchmarks showed that handing the history to a generic third-party summarizer agent resulted in performance degradation on subsequent tasks. The external agent lacked the implicit reasoning state of the active worker, resulting in generic summaries that stripped out critical technical nuances.
The Fix: Asynchronous Self-Summarization
We moved to an Asynchronous Context Compaction model that solves both problems.
- The 70% Trigger: We don't wait until the cliff edge. When context usage hits 70%, we trigger a background job.
- Non-Blocking Execution: The user doesn't see this happen. The main agent continues responding to new queries using the full (un-compacted) context, maintaining zero latency.
- Hot-Swapping: When the background task completes, we carefully splice the state. We replace the old history (up to the trigger point) with the new summary, but we keep the new messages (generated while the background task was running) raw and untouched.
Why Self-Summarization Wins: Crucially, we don't spawn a new "Summarizer" persona. We ask the active agent itself to "Summarize your work so far" in that background thread. Because the agent summarizes its own conversation, it intuitively preserves the details relevant to its current goal, rather than creating a generic recap.
This approach eliminated the "maintenance pause" entirely and improved long-context task completion rates by keeping recent context raw and immediate.
The "Cache Trap" in Summarization
Even with asynchronous execution, you still have to pay for the tokens to generate the summary. Here is where most teams lose money. When it's time to summarize, the instinct is to change the system prompt to: "You are a summarizer."
This is a trap. Changing the system prompt breaks the cache for the entire history. You effectively pay full price to re-read 100k tokens just to throw them away.
The Fix: Append, Don't Replace
The fix is simple: Don't touch the system prompt. Just append a final message: "Summarize the conversation above." This keeps the 100k tokens in the cache (90% discount).
Claude Sonnet 4.5 pricing: $3/MTok input, $15/MTok output, $0.30/MTok cache read
❌ NAIVE: Create new system prompt with summarization instructions → breaks cache
{
"system": [
{
"type": "text",
"text": "You are a summarizer agent..." # New system prompt (~500 tokens)
},
],
"messages": [
# Old messages to summarize (100K tokens)
# CACHE BROKEN - must reprocess as uncached input!
{"role": "user", "content": "Message 1..."},
{"role": "assistant", "content": "Response 1..."},
...,
{"role": "user", "content": "Message 50..."}
]
}
Cost breakdown: 500 tokens uncached ($0.0015) + 100K uncached ($0.300) + 2K output ($0.030) = $0.3315
✅ OPTIMIZED: Preserve original system prompt + append summarization instruction → preserves cache
{
"system": [
{
"type": "text",
"text": "You are Anna..." # Original system prompt (~8K tokens, already cached)
},
{"cachePoint": {"type": "default"}} # Cache hit!
],
"messages": [
# Old messages to summarize (100K tokens)
{"role": "user", "content": "Message 1..."},
{"role": "assistant", "content": "Response 1..."},
...,
{"role": "user", "content": "Message 50..."},
{"cachePoint": {"type": "default"}}, # Cache all old messages
# Summarization instruction at the END (~500 tokens, not cached)
{
"role": "user",
"content": `Summarize the conversation above.
Extract: key decisions, technical analysis, errors, current state.`,
},
],
}
Cost breakdown: 8K cached ($0.0024) + 100K cached ($0.030) + 0.5K uncached ($0.0015) + 2K output ($0.030) = $0.0639
Savings: 80.7% cost reduction ($0.3315 → $0.0639)
Trade-offs and Recursive Summarization: Summarization loses some conversational nuance and fine-grained detail. We mitigate this through comprehensive summary templates that preserve technical decisions, error patterns, and user feedback—ensuring agents maintain continuity across compaction boundaries.
For extremely long sessions, we apply recursive summarization: existing summaries get included in subsequent passes, creating hierarchical compression where older context becomes progressively condensed while recent context remains detailed.
3.3 Tool Consolidation
Anthropic recently introduced the Model Context Protocol (MCP) as a standard for connecting agents to data. It's a massive step forward—standardizing how agents connect to everything from Slack to Postgres.
The "Tool Pollution" Paradox
MCP makes it easy to connect tools. Too easy. Suddenly, your agent has access to 500 tools. If you dump 500 tool definitions into the context window, you leave no room for reasoning. The agent spends 90% of its brainpower just parsing the API list, or worse, hallucinates parameters because the context is flooded.
The "Code Execution" Pivot (and why we use it sparingly)
To solve this, Anthropic also proposed Code Execution with MCP, suggesting agents write code to "discover" tools dynamically. Instead of listing tools in the system prompt, you give the agent an execution environment and let it import tool definitions from a file tree.
The Reliability Trade-off
While progressive disclosure is efficient, we found that for our use case, keeping critical tools visible is essential. In CloudThinker, reliability is our primary goal. We think that if an agent doesn't explicitly see a "Restart Database" tool in its system prompt, it is less likely to reason about using it as part of a complex solution.
The CloudThinker Solution: Consolidated Tools + JIT Schemas
We chose a pragmatic middle ground: Consolidate the interface, hide the manual.
Traditional CRUD agent design creates five separate tools (recommendation_list, recommendation_get, recommendation_create, recommendation_update, recommendation_delete). We merge these into a single interface.
# Minimal description + schema externalized to get_instruction
@tool(description=MINIMAL_RECOMMENDATION_TOOL_DESCRIPTION)
async def recommendation(
command: Literal["get_instruction", "get_all", "delete", "create", "update"],
recommendation_ids: list[UUID] | None = None,
recommendations: dict | None = None, # Generic dict instead of typed schema
) -> str:
The "Just-in-Time" Schema
Notice the get_instruction command? That's our secret weapon.
Instead of stuffing the full schema into the system prompt (where you pay for it on every token), we hide it behind this command.
- Visibility: The agent sees the
recommendationtool. It knows the capability exists (unlike Code Execution). - Efficiency: It doesn't pay for the parameter definitions until it needs them.
If the agent forgets how to update a recommendation, it calls recommendation(command="get_instruction") to get the manual. This moves documentation from "Always Loaded" (expensive) to "On Demand" (cheap), maintaining reliability without the token bloat.
3.4 Parallel Tool Calling
Early LLM agent architectures were fundamentally sequential. The ReAct pattern (Reasoning and Acting), introduced in 2022, defined the standard approach: the LLM calls one tool, analyzes the outcome, reasons about the next step, then executes another tool call. This sequential workflow was by design—models weren't trained to handle multiple simultaneous operations, and frameworks enforced one-tool-at-a-time execution to maintain reliability.
The landscape shifted dramatically in 2024. When Anthropic announced Claude 3's tool use general availability in May 2024, parallel tool calling was initially unsupported. However, as foundation models became more capable, providers began training them to handle concurrent operations. Modern Claude models now support calling multiple tools simultaneously within a single response—a critical evolution for complex workflows requiring independent operations.
Enabling Parallel Tool Calling
Model capability alone isn't sufficient—you must explicitly instruct agents to leverage parallelism. Modern models default to sequential execution unless prompted otherwise. As Anthropic's documentation recommends: "For maximum efficiency, whenever you need to perform multiple independent operations, invoke all relevant tools simultaneously rather than sequentially." This single instruction can reduce multi-tool workflow latency by 3-5x compared to sequential execution.
In CloudThinker, parallel tool calling emerges naturally during plan execution. When an agent marks a plan step completed and transitions to the next task, it evaluates whether multiple operations can run concurrently. For example, completing "gather cost data" might trigger parallel steps for "analyze compute patterns," "review storage utilization," and "audit network traffic"—all executing simultaneously rather than sequentially, reducing multi-step workflows from minutes to seconds.
This isn't just about speed (though it cuts latency by 3-5x). It's about money. Every round trip to the model costs you tokens. By batching 5 tool calls into one request, we cut out 4 round trips of context processing. That simple change drove a 30-40% cost reduction for our complex workflows.
4. Conclusion
We learned the hard way that multi-agent systems fail predictably—and succeed through disciplined optimization.
The supervisor-worker pattern proved essential for operational clarity—predictable failures, traceable routing, and observable trade-offs. But remember the golden rule:
Complexity is a choice.
Start with a single agent. Add prompt caching. Instrument everything. Only when metrics demand it, evolve to a supervisor pattern. Scale when metrics justify complexity.